node调用python进行ocr文字识别
起因
最近翻看项目,找到了之前学习时候写的一个爬虫影视站的项目。主要是使用node对页面的元素进行分析,然后组装数据。然后正好在看UI设计时候有一个比较好看的移动端的影视app设计图,然后就把之前的代码又翻看了一下,基本功能效果也都有,但是之前的搜索逻辑现在是使用不了了,因为源站现在增加了搜索的验证码功能,所以就有了下面的实践。
Tesseract.js 实现效果
最初呢,因为原来使用的是node写的一个项目,自然就想着有没有什么好用的js包,然后一圈搜索下来,也就tesseract.js提到的文章多一些 然后我就想着,既然这么多人用了,那应该还是不错的吧,然后开始coding,但是一番折腾下来 发现并没有很好用,主要是识别的正确率不是很高,然后我想着反正是自己用的 错了就重试几次得了,然后抱着这个想法在我用了十分钟之后 我就放弃了..... 这玩意错误率不是一般的高。当然也许是我的模型不行.
js
const Ts = require(tesseract.js')
const path = require('path');
const sharp = require('sharp');
let im = path.join(__dirname, 'debug','7.png')
sharp(im)
.threshold(220) // 自定义二值化,阈值可调
.blur(0.4) // 轻微模糊,去除小噪点
.toFile('output.jpg')
.then(async () => {
console.log('Image processed successfully!');
let imagePath = path.join(__dirname, 'output.jpg');
let { data: { text } } = await Ts.recognize( imagePath , 'eng',{
// logger: m => console.log(m)
})
console.log('识别验证码:',text);
});效果图(这样的一张图片给我识别成这样,当然如果进行参数微调 有时候也是可以识别出来的)
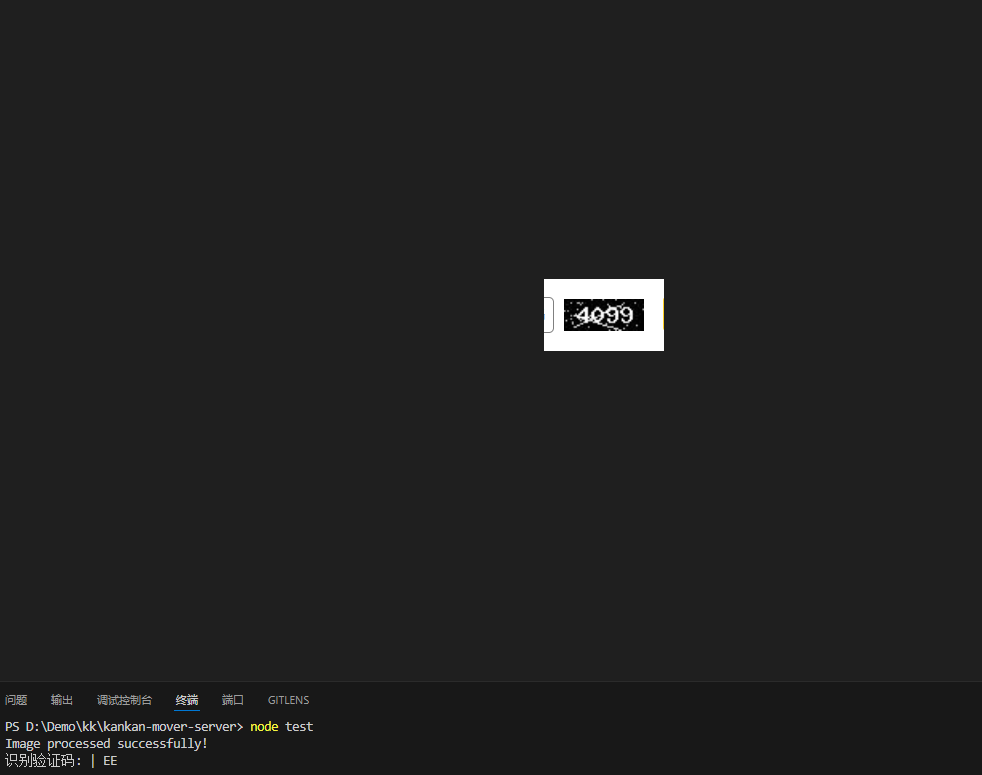
但是有一说一 你这一张是微调出来了,但是下一张,保不齐又要进行调整.....
切换思路,调转枪头
终于,我实在是受不了了,我想起来了python,不得不说,在人机这一块python确实是一个字NB,python里面呢 我是使用了easyocr这个库,这一下子正确率 唰的就起飞.
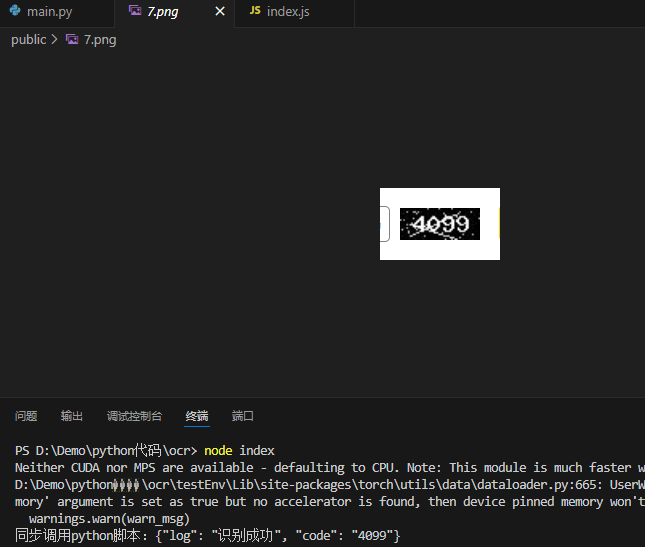
先看一下效果
同样的一张照片 直接识别成功
js
const { execSync,exec } = require('child_process')
// 在node脚本中运行python脚本-同步
const runPythonInNodeEnvSync = () => {
// ${process.cwd()} 获取当前脚本运行目录
const path = `${process.cwd()}/main.py`;
const data = execSync(`python ${path} public/7.png`,{ encoding: 'utf-8' });
console.log(`同步调用python脚本:${data.toString()}`);
}
runPythonInNodeEnvSync()
python
import easyocr
import os
import sys
import json
import io
# 初始化 easyocr 识别器,支持英文
reader = easyocr.Reader(['en'])
# 强制 Python 输出 UTF-8 编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
# 返回结果字典
result_dict = {}
# 参数判断
if len(sys.argv) < 2:
result_dict['log'] = '请输入图片路径'
result_dict['code'] = None
print(json.dumps(result_dict, ensure_ascii=False))
exit()
imgPath = sys.argv[1]
# 图片路径判断
if not os.path.exists(imgPath):
result_dict['log'] = '图片不存在'
result_dict['code'] = None
print(json.dumps(result_dict, ensure_ascii=False))
exit()
# 开始识别
ocr_result = reader.readtext(imgPath)
if ocr_result:
result_dict['log'] = '识别成功'
result_dict['code'] = ocr_result[0][1] # 只取第一个识别结果
else:
result_dict['log'] = '未识别到结果'
result_dict['code'] = None
# 最后返回 JSON 格式
print(json.dumps(result_dict, ensure_ascii=False))文章标题:node调用python进行ocr文字识别
文章作者:Cling.
文章链接:[复制]
最后修改时间:2025年 06月 27日 12时10分
商业转载请联系站长获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。 本文采用CC BY-NC-SA 4.0进行许可。
Copyright © 2023-2026
豫ICP备2022014268号-1
「每想拥抱你一次,天空飘落一片雪,至此雪花拥抱撒哈拉!」
本站已经艰难运行了989天